An Introduction into Kafka World
December 14, 2025 • 9 min read
KafkaApachePartitionsTopicsDistributedOpen Source
Introduction
Apache Kafka is a popular, distributed event streaming platform developed originally by LinkedIn. Then, it was open sourced and handed over to Apache later. As per the suggestions from some articles, it is indeed a distributed commit log. As a log ( which is one of the simplest data structures), it has below attributes
- Ordered. Appends new records at the end.
- Immutable. You cannot edit or delete a record once added. Edit or delete can be done as a new record.
- Location of each record is constant and known. Therefore, can access easily
Why Kafka
With the distributed nature of modern day applications, it is often require to establish communication between different components or applications in an ecosystem. These components may be made with different technology stacks, by different teams and hence require different ways to connect. For simplicity, let's assume all components communicate via REST APIs over HTTP. Still, different components that export data will expose APIs with different schemas. This makes each client application becomes couple with these schemas for the communication. For instance, consider an airline business with below components.
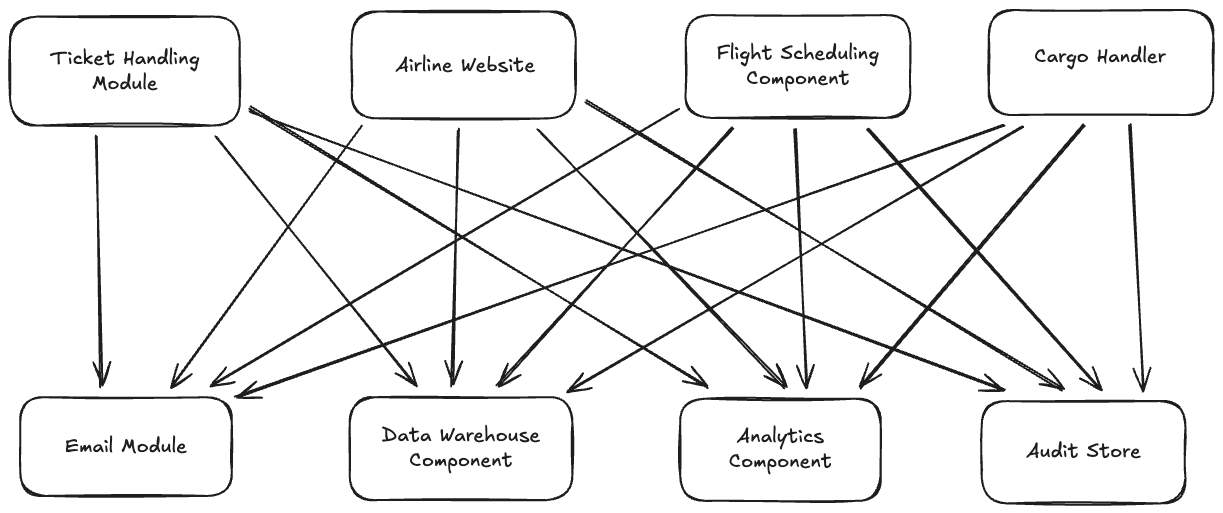
This is hard to maintain. With the number of applications/components grows, this becomes much more complex and harder to maintain. Kafka can resolve this problem as below by decoupling these system dependencies.
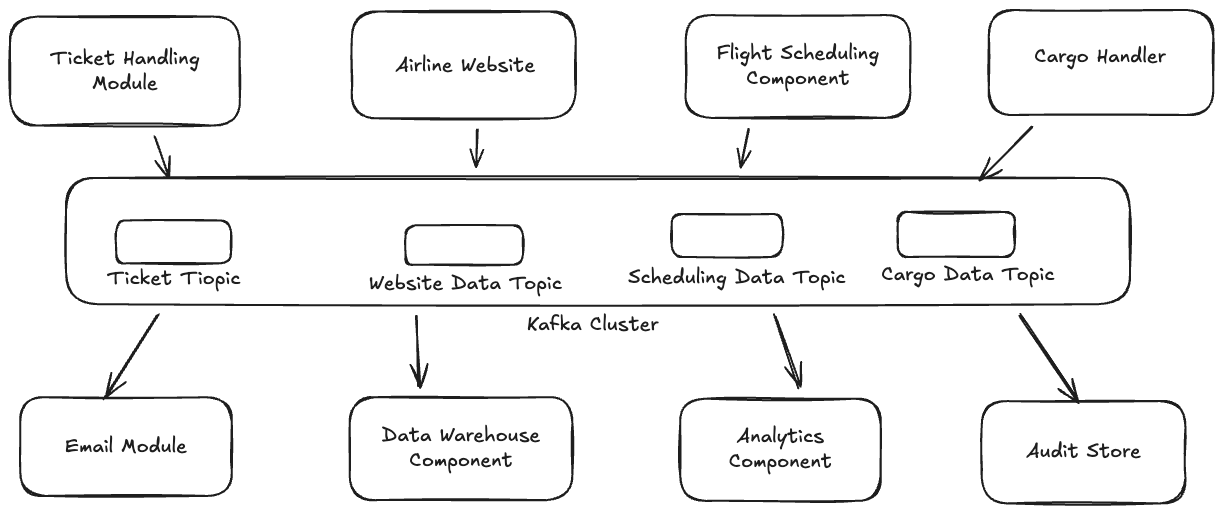
Additionally, Kafka is distributed and resilient application with fault-tolerant ( We will explore these attributes later in this article). Due to this distributed nature, it can be scaled horizontally ( by adding more servers/clusters). Therefore, Kafka can deliver high performance based on the requirement.
Kafka is used by many companies worldwide including fortune 500 companies for use cases ranging from activity tracking, location based metrics gathering, stream processing and messaging systems.
Topics and Partitions
Topics
A Topic is a stream of data. Kafka stores data in topics. Topic can be identified by its name. You can create as many topics as you want. The only constraint is you are required to give a unique name to it. ( Name should be unique in your kafka cluster).
Partitions
A topic contains 1-to-many partitions. Number of partitions is specified when the topic is created. You can increase the number of partitions later as well. But you cannot decrease the partition count later as it affect the data already resides in the partitions. When a message is placed in a partition, it receives an incremental id called "offset". The message can be uniquely identified with the kafka topic, partition and this offset number.
Order of Data
When a message is written to a topic, partition is getting selected randomly ( unless a key is provided. More about the topic "key" will be discussed later in this article). Data within the partition is ordered. But data within the topic cannot be considered in any order.
Retention Time
Data is kept in topics for a limited time only. This is a configurable time period. This is called "Retention time". Once the retention period is over, messages are getting deleted from the cluster( and from the topic and partitions). But the offset of the deleted messages are never reused.
Brokers
Kafka cluster comprises multiple servers / nodes. These are called brokers in the kafka domain. Each broker is identified by an integer id.
Each broker contains certain topic partitions. Ideally all the partitions of a particular topic is never resides within single broker ( unless cluster only has one broker).
More brokers means high amount of distribution. And this results in high resilient and fault tolerance.
Kafka brokers in a single cluster are interconnected with each other. Therefore, producers or consumers does not need to connect to each cluster. They can connect to one such instance and consume / produce messages from / to all the topics.
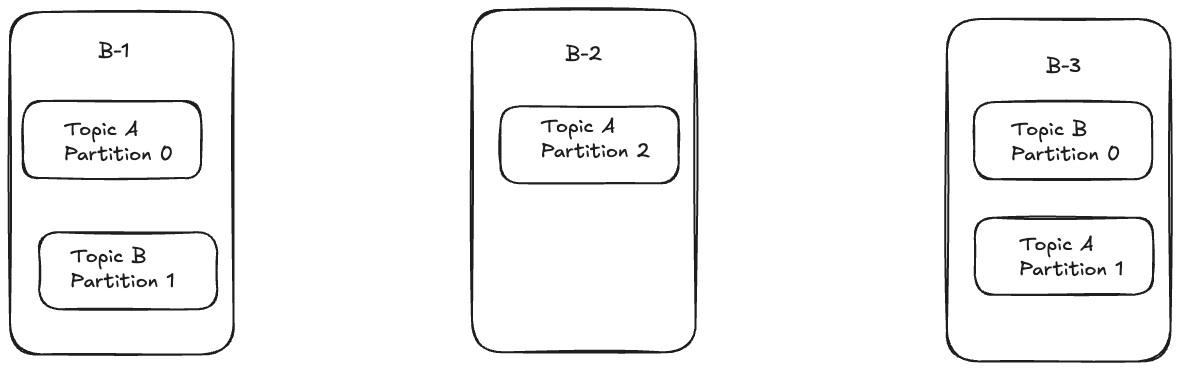
Example - 1
Let's take a scenario where we have a cluster with 3 brokers ( B-1 , B-2 and B-3). If we create two topics A ( 3 partitions) and B ( 2 partitions). If the replication factor is 1 ( which we will be talking about next), below is how it will look like.
Replication Factor
Partitions will be replicated across the broker based on the replication factor. Replication factor should always be greater than 1 ( Which means more than 1 replica should present for all partitions). Usually, this value is set to 3 by default. This helps when a broker is down where another broker can take that place and start serving immediately.
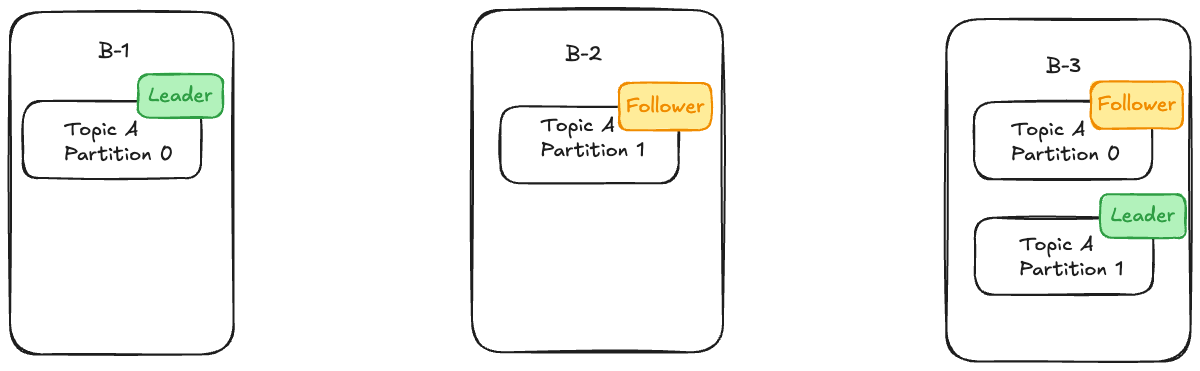
Leader, Followers and In-Sync Replicas(ISR)
One of the replicated partitions will act as the leader. All the producers writes to the leader and all the consumers read from the leader( In normal kafka setups). The leader decides the order of messages and the offset of a message.
Followers are the rest of the partitions that is not the leader. They do not allow producers or consumers to write or read. They just sits in brokers and copy the same log from the lead. The purpose of the follower is to be in sync with the leader.
In-Sync replica(IR) is a subset of followers who are
- Reachable
- is not lagging behind the leader beyond allowed lag window ( replica.lag.time.max.ms configuration on brokers)
If a follower falls behind or is unreachable, it gets kicked out from ISR until it catches up.
Example - 2
Let's take a scenario where we have a cluster with 3 brokers ( B-1 , B-2 and B-3). If we create only one topics A ( 2 partitions) and the replication factor is 2 ( which we will be talking about next), below is how it will look like.
Producers
As mentioned earlier, producers ( Applications who wants to write data to kafka topics) can connect to any of the brokers, specify the topic name to start producing messages. Kafka automatically takes care of identify partitions, which partition to put this message, and handling replications. Producers can decide on which acknowledgement they want to use based on their requirement as below.
- Acks = 0 | Producer will not wait for the acknowledgement (This could lead in possible loss of data. But this will result in maximum throughput as waiting is minimum)
- Acks = 1 | Producer will wait for the leader acknowledgement. ( Limited loss of data)
- Acks = all| Producer will wait for acknowledgement of all replicas. ( No loss of data. Less throughput).
Key Parameter
Usually, the partition of the topic is decided randomly when a message is received to a topic. But this behaviour can be controlled using the parameter 'key' in the kafka message. When 'key' is not defined, partition will be selected randomly. But when the 'key' is defined, kafka will ensure the messages with same key will ends up in the same partition. This will results in message ordering for the messages with the same key ( Since messages are ordered within the partition).
Consumers
Similar to producers, consumers ( Applications who wants to read data from kafka topics) can connect to any of the brokers and start consuming messages in a topic. Kafka will take care of pulling data from correct partition replica. Consumers will read data elements in each partitions in order they are in. But also they could read data from other partitions as well in the same time.
Consumer Groups
Consumers are organized in consumer groups. A consumer group is a collection of consumer applications that works together to consume all messages from a topic. These app does not talk to each other for coordination. They will have the same group_id configuration and kafka will identify that they are belong to the same consumer group and will do the coordination part for them. Kafka will ensure one partition is read only by one consumer. But same consumer can read from multiple partitions ( Based on the number of partitions and number of consumers available in the consumer group). Any number of consumer groups can read from a topic. Kafka will ensure all data is sent to all consumer groups.
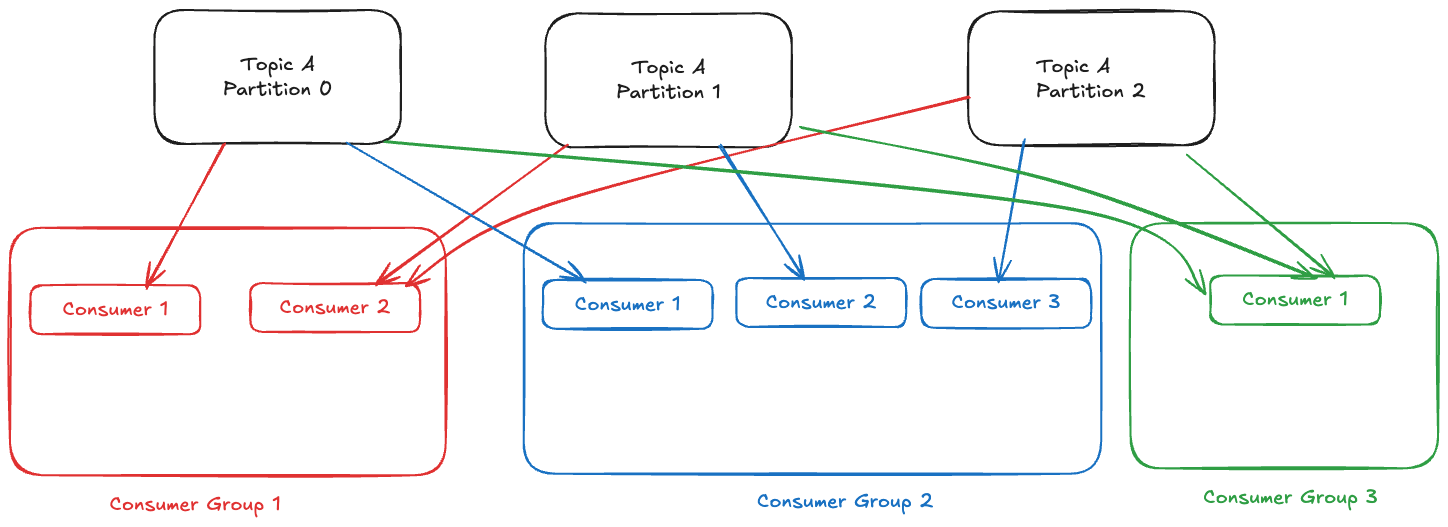
Example - 3
Consider the below example with a single topic with 3 partitions and 3 consumer groups reading that topic.
Group Coordinator
A specific broker is assigned as the group coordinator to maintain a consumer group memberships. This same group coordinator also responsible for save the consumed offsets ( Also known as offset commits). This data will be stored in internal topic named "__consumer_offsets". This topic also contains metadata about the consumer group. This allows group coordinator broker to fail and hand the responsibility to another broker.
Group Rebalance
Group Rebalance is an action taken by kafka where every group member forced to drop and rejoin the group. After rebalancing act, each consumer may receive a same of different partition(s) to consume. Based on the offset commit done before rebalancing act, it will continue to consume. Rebalancing could be initiated due to several reasons such as,
- A Consumer Joins the group
- A Consumer Shutdown
- A Consumer dies
- rebalance API called
- New Partition is added to the topic etc.
Heartbeat
Each consumer in a consumer group maintains a health API call called heartbeat with the group coordinator. This is done in a defined time interval called heartbeat_interval_ms If the response from the coordinator for the heartbeat indicates a rebalance is required, consumers will initiate the rejoining process.
Controllers
Brokers also require some sort of coordination as they are also distributed. Broker coordination is achieved using a specific brokers called controllers. At any given time, there will be only one "Active Controller". The other controllers are called standby controllers. Controllers are responsible for many things. One of the main such responsibility is handling broker failures. If a broker failed, partition leaderships may require to reassign. All the metadata related to cluster is stored in a special kafka topic ( which replicates over all controllers).