Blueprint: Persist Kafka Audit Messages to Postgres with Kafka Connect (No Schema Registry Required)
February 18, 2026 • 7 min read
KafkaKafka ConnectPostgreSQLSink ConnectorSMTDocker ComposeEvent StreamingData EngineeringPerformanceAudit LogsConfluent
Introduction
In this blog post, I am sharing my blueprint implementation to save Kafka messages in relational database (Postgres) using Kafka Connect. While this may not be the only way to achieve this, this is the easiest and most easy-to-maintain approach I have found so far.
Background
Few years ago, I came across this requirement (as part of my work as a Software Engineer) to backup stream of audit messages in a Kafka topic into a relational database. Even though there were many ways to achieve that, I chose to implement a custom java microservice (using Spring Boot and Apache Camel) at that point to consume Kafka messages. This worked great for us for around 2 years until we hit a performance issue. One of the processes that we were working on was generating around 200K records in a short period (1-2 hours) and my custom microservice to consume audit records took 1.5 days to consume all these audit records. Our original plan was to improve the existing microservice by introducing more parallelism into the processing ( improving the bottlenecks in the code), increasing resources of the k8s deployment ( vertical scaling) or adding more instances of the same microservice so that each Kafka partition in the source topic will be processed by a separate instance ( horizontal scaling). While working on the initial research on this improvement, I came back to fundamental requirements and tried to evaluate alternative approaches to solve the same problem. As a result of that, I came across with the Kafka Connect Postgres Sink Connector and decided to try it.
Kafka Connect
Kafka Connect is a free and open-source component that acts as a hub between Kafka and other data handling mechanisms. We can put as much as connectors/plugins in any Kafka Connect instance to manage data in and out. For instance, we can put a connector to store data from Kafka topic into a S3 bucket. On the other hand, we can put another connector to pull data out from relational database such as MySQL and push to a Kafka Topic.
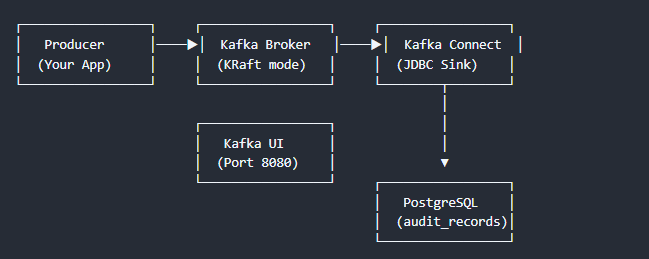
Architecture
The idea is simple here. To achieve our requirement mentioned above, we will place a Kafka connect instance between Kafka and Postgres Database. We can use the existing Postgres sink connector from the confluent connector store to process the messages.
Proof of Concept (PoC)
I used docker and docker compose to do the PoC for this. First, I had to build a custom docker image with the base Kafka Connect image to include the Postgres sink connector and SMT Transformer component.
What is SMT Transformer
Postgres Sink Connector expects Kafka messages to have a schema along with it. Either the schema should be embedded (both message values and schema are in the same JSON) or linked schema registry should contain the schema for all messages in the topic. But in my requirement, it was not possible to do any of this (since this was an already existing data stream). So, I had to introduce a simple custom Java component with just one class to convert the plain message to have schema within it. Source code of the SMT Transformer can be found here. This contains single pom file and single Java file as in the provided link. In addition to binding the schema into the message, this transformer validates the messages strictly for the types.
Custom Kafka Connect Image
I created a DockerFile to build this custom image as below.
# ─────────────────────────────────────────────────────────────────────
# Stage 1 – Build the custom SMT JAR and collect PostgreSQL driver
# ─────────────────────────────────────────────────────────────────────
FROM maven:3.9-eclipse-temurin-17 AS builder
WORKDIR /build
COPY kafka-connect-smt/ .
RUN mvn clean package -DskipTests -q
# ─────────────────────────────────────────────────────────────────────
# Stage 2 – Kafka Connect runtime with all plugins
# ─────────────────────────────────────────────────────────────────────
FROM apache/kafka:4.1.1
USER root
# Create the plugin directory expected by connect-distributed.properties
RUN mkdir -p /opt/kafka/plugins/jdbc-sink
# Download Aiven JDBC Connector (compatible with Kafka 4.x)
RUN cd /opt/kafka/plugins/jdbc-sink && \
wget -q https://github.com/Aiven-Open/jdbc-connector-for-apache-kafka/releases/download/v6.10.0/jdbc-connector-for-apache-kafka-6.10.0.zip && \
unzip -q jdbc-connector-for-apache-kafka-6.10.0.zip && \
mv jdbc-connector-for-apache-kafka-6.10.0/* . && \
rm -rf jdbc-connector-for-apache-kafka-6.10.0 jdbc-connector-for-apache-kafka-6.10.0.zip
# Copy the PostgreSQL driver and the custom SMT
COPY --from=builder /build/target/plugins/ /opt/kafka/plugins/jdbc-sink/
COPY --from=builder /build/target/audit-record-smt-1.0.0.jar /opt/kafka/plugins/jdbc-sink/
USER appuser
You may notice that there are two stages for this docker file. First stage is to build the SMT. Second stage is the one that takes that SMT Jar, download connector plugin(from Aiven Github repo), unzip and move everything to plugins directory within the original Kafka connect image.
Docker Compose file for testing
For the testing purpose, I assumed we have a Kafka topic named “Audit-Records.JSON” contains messages in the below format.
{
"messageId": "<A Random UUID (Primary Key of the message)>",
"timestamp": <Unix Timestamp of the message published>,
"requester": "<ApplicationName>",
"direction": "REQUEST",
"metadata": "<JSON Key value pairs>",
"format": "<Format of the message>"
}
Below is a sample message in the above format.
{
"messageId": "d1c452a2-7ba4-4e18-8366-7ffafaed3bed",
"timestamp": 1771138537,
"requester": "MyApplicationName",
"direction": "REQUEST",
"metadata": "{\"key1\":\"value1\",\"key2\":\"value2\"}",
"format": "application/xml"
}
I created a docker compose file (of course with the help of GitHub copilot) that consists of Kafka (without zookeeper since I used Kafka 4.1.1), Postgres, init container (to include Kafka topics ), Kafka UI and the custom Kafka connect image that we built in the previous step
Some things to highlight
- Postgres instance is using this script to initialize the database required to store the data defined in the sample. If you are using this blueprint, define according to your requirement.
- You may find the configuration properties used to start the Kafka Connect in this location. (In the docker compose file, this is mounted inside the docker image)
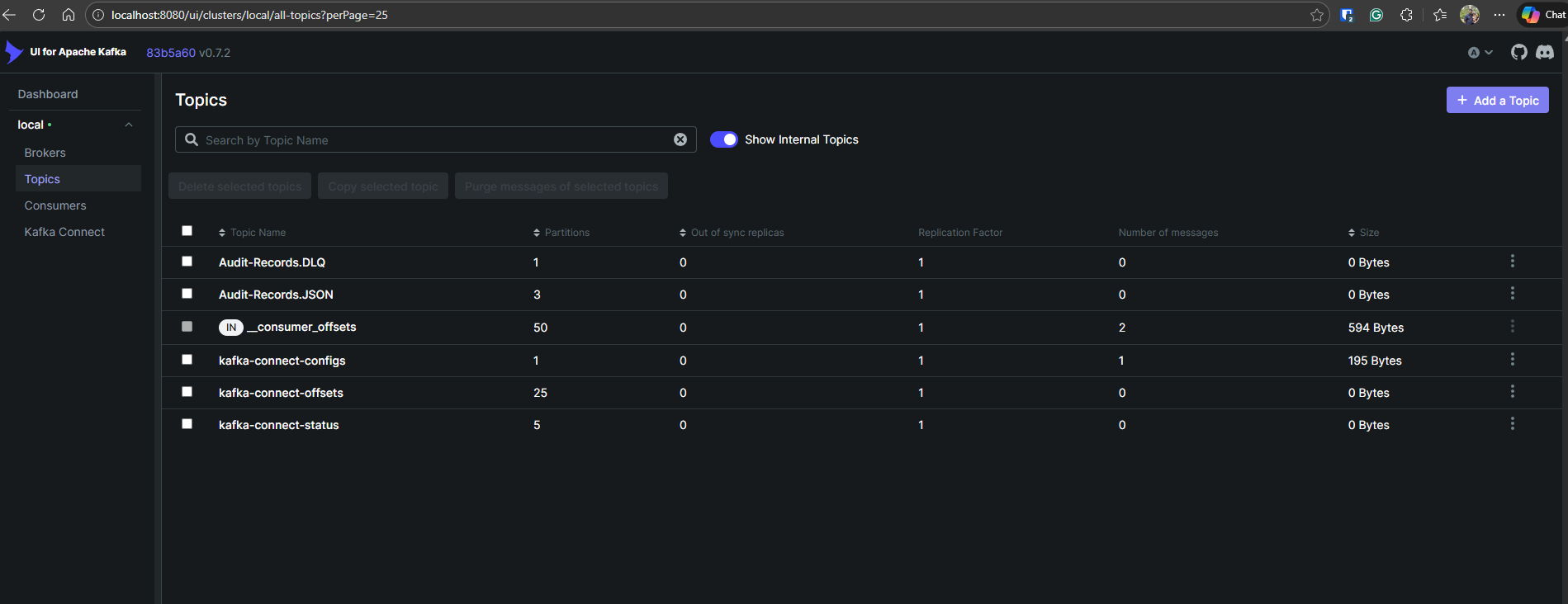
- Kafka UI is simply connecting to Kafka instance and Kafka Connect instance. You can observe the topics and deploy Kafka connect plugins as shown in the screenshots below
- I did not worry too much about security (authentication mechanisms of the components) in this POC as it is out of scope for the theory being tested.
You can get this whole setup from this GitHub repository.
To start this, you can use the command below.
docker-compose up -d --build
Then you can navigate to Kafka UI ( http://localhost:8080/) and check Kafka topics are created as expected.
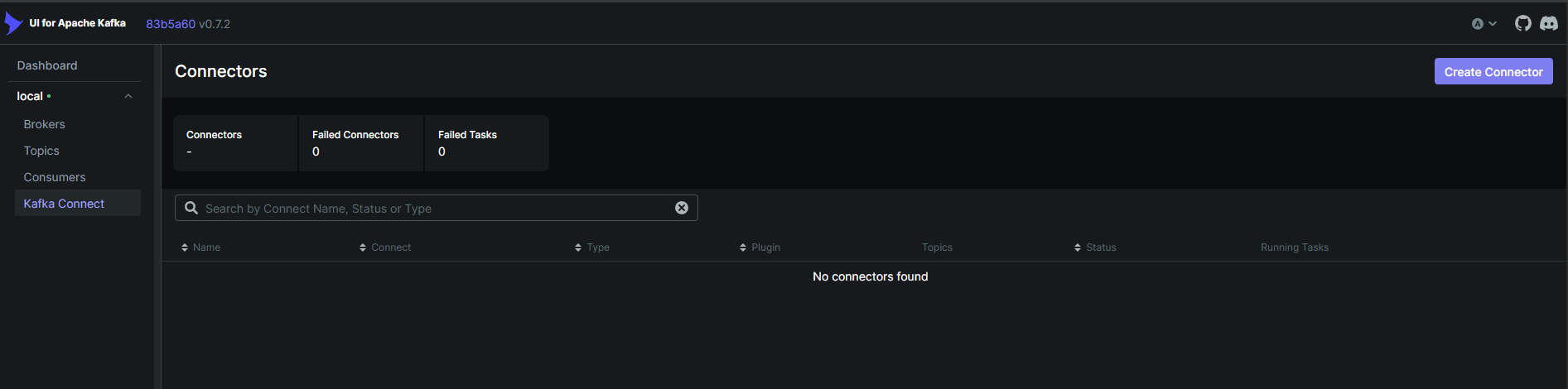
In the Kafka Connect UI, you may note there are no plugins registered.
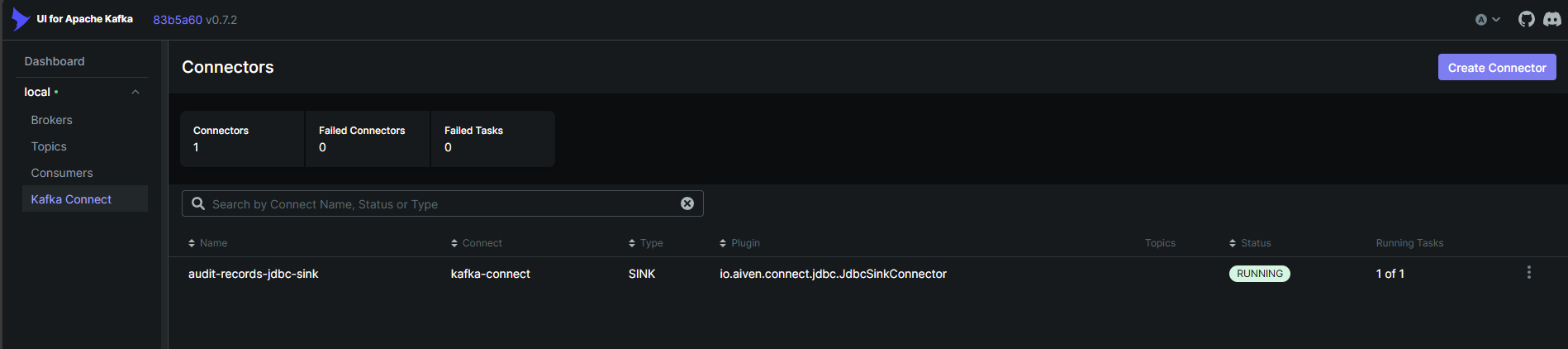
Next step is to register our plugin. You can use the REST API of Kafka Connect for this purpose. Required body parameters can be found in connectors/sink-connector.json in the repository.
curl -X POST -H "Content-Type: application/json" --data @connectors/sink-connector.json http://localhost:8083/connectors
Now you may note the plugin registered in the Kafka Connect via Kafka UI as below.
Let’s publish the below sample message now for testing as below using Kafka UI. Paste the message and click on publish.
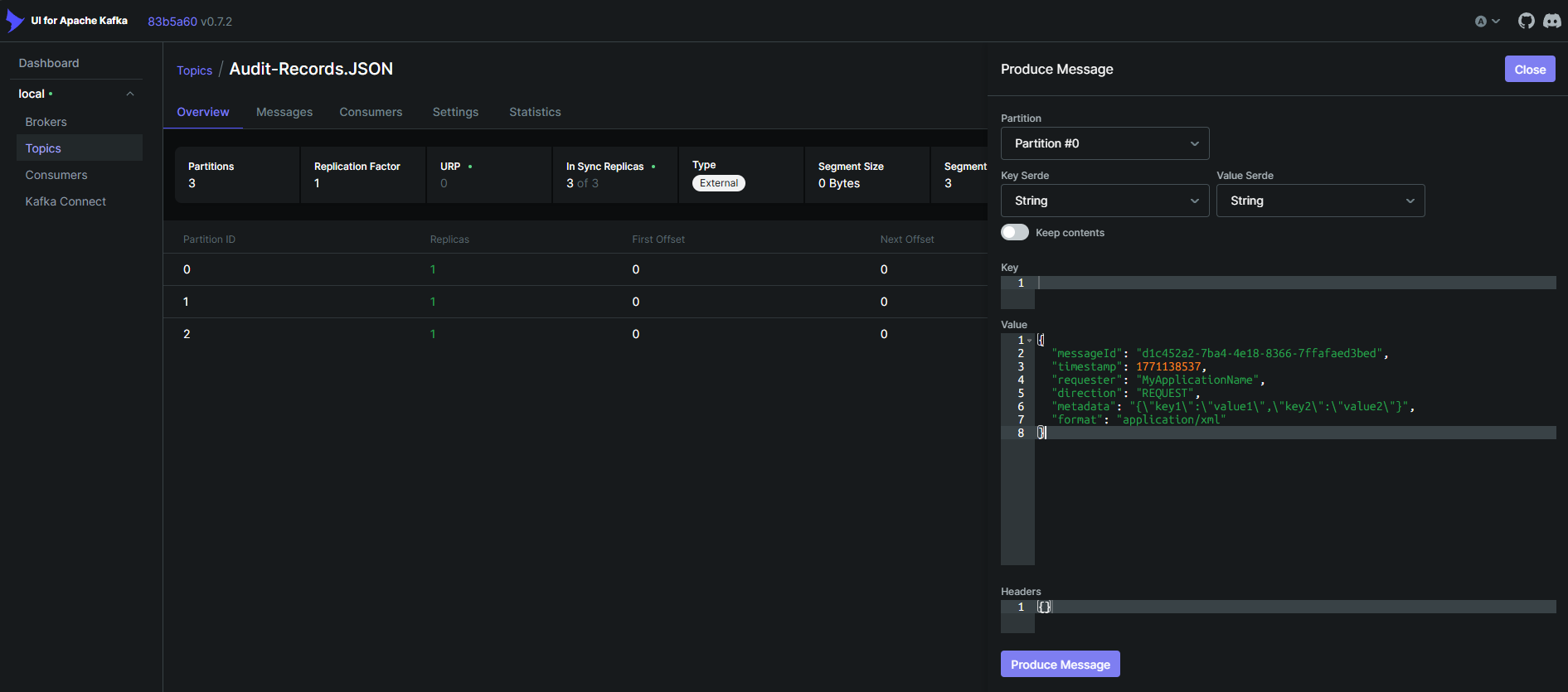
Open the database in any of the preferred clients (using the username and password given in the docker compose) and check the record is getting published to the database table as below.

Conclusion
We conducted the test for a large number of records as well. We were able to notice that this Kafka connect setup is able to consume 200K records within 10 mins. This is much more maintainable as well for us as we are not overseeing much code in our side. Therefore, we can conclude, using Kafka connect for a requirement like this is much easier to test, maintain and support.